


Cuando los buscadores aprenden a pensar
La revolución silenciosa de la búsqueda agentiva

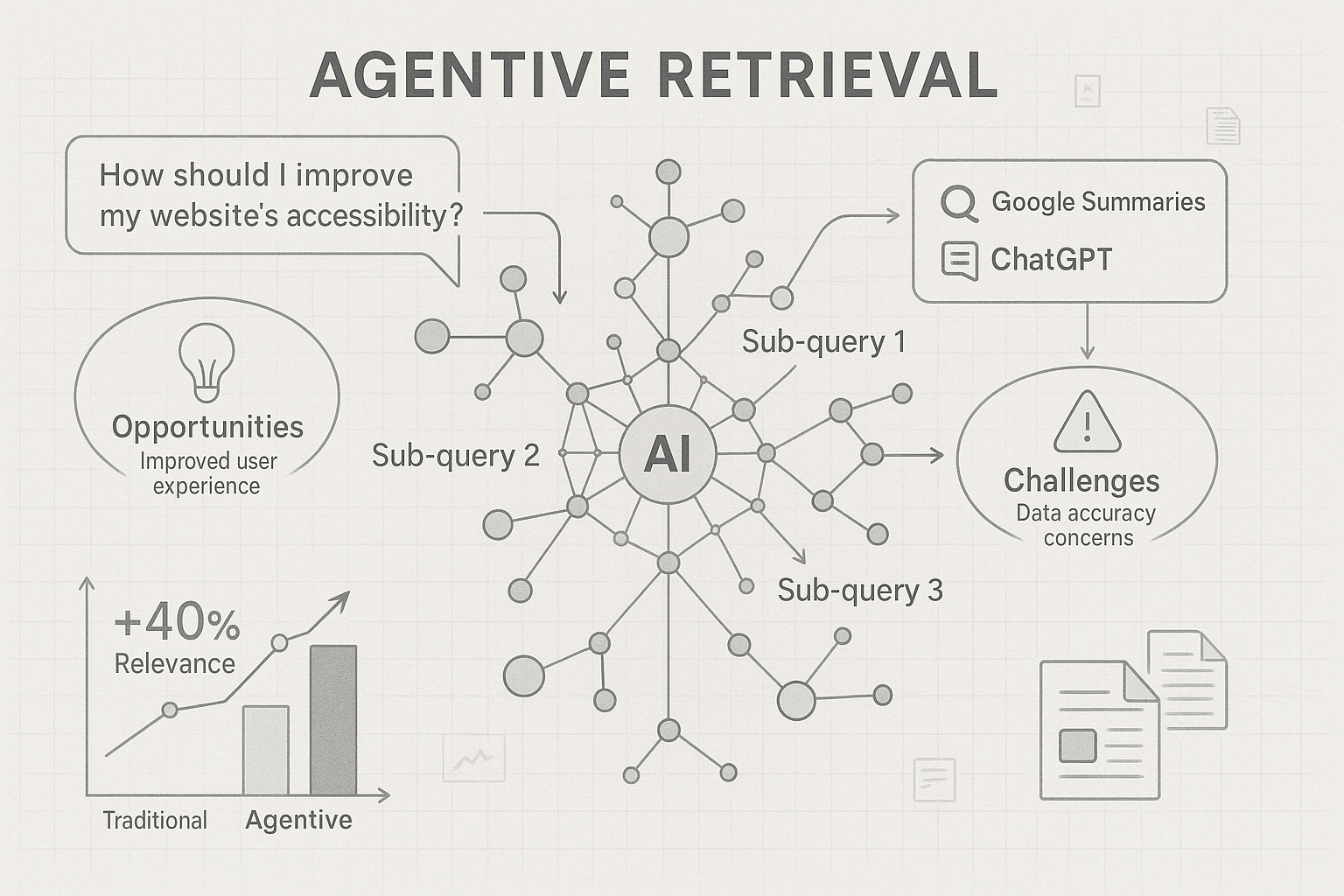
¿Te has preguntado alguna vez por qué ChatGPT con búsqueda web o Perplexity.ai parecen entender mejor tus preguntas complejas que la cajita de Google (al menos hasta ahora)? La recuperación basada en agentes está transformando la forma en que los algoritmos buscan información.
Imagina por un momento que, en lugar de hacer una sola pregunta, tuvieras un asistente que primero analiza tu consulta, la descompone en partes más manejables y luego orquesta múltiples búsquedas especializadas para darte una respuesta completa. Vamos, el proceso que seguías habitualmente sin darte cuenta y eso es exactamente lo que está pasando bajo el capó de estos nuevos sistemas de búsqueda inteligente.
El nacimiento de los buscadores que razonan (o de los razonadores que buscan)
La búsqueda tradicional ha funcionado durante décadas con un modelo simple, el de una consulta, una respuesta. Pero la realidad es que muchas de nuestras preguntas son como una cebolla, tienen capas. Cuando preguntamos "¿Cómo afecta el cambio climático a la agricultura y la salud?", en realidad estamos haciendo dos preguntas relacionadas pero distintas que requieren enfoques diferentes.
Los agentes de búsqueda han llegado para cambiar esta dinámica. El agente realiza una planificación de consultas con una sola llamada al LLM, lanza múltiples búsquedas en paralelo y finalmente combina los resultados relevantes. Es decir, estos sistemas no solo buscan, piensan antes de buscar.
La diferencia es como comparar un pescador que lanza una sola red gigante versus uno que estudia las corrientes, identifica los mejores puntos y lanza varias redes especializadas simultáneamente. Obviamente, el segundo va a tener mejor pesca.
Números que no mienten
Los resultados de esta nueva aproximación son contundentes. Microsoft informó incrementos de hasta +33 puntos en relevancia de respuesta al aplicar un agente de búsqueda frente a una búsqueda tradicional en consultas complejas. Para ponerlo en perspectiva, eso significa pasar de encontrar información medio relevante a encontrar exactamente lo que necesitas.
Pero no es solo Microsoft. Parece que generar múltiples subconsultas para cubrir distintos aspectos de la pregunta produjo un aumento de +2.3 puntos en Recall@100 y +3.2 en MAP. Estos no son incrementos marginales, son saltos cualitativos en la precisión de la búsqueda.
¿Y qué significan estas métricas técnicas en la práctica? Imagina que antes encontrabas la respuesta correcta en la décima posición de los resultados, ahora la encuentras en la tercera. O que antes solo el 60% de los documentos que te mostraba el buscador eran realmente útiles, ahora es el 85%.
¿Cómo funciona el “agentic retrieval”?
El proceso es muy simple en su concepto, pero sofisticado en su ejecución. Cuando haces una pregunta compleja, el sistema LLM (como GPT-4o) actúa como un director de orquesta, analizando tu consulta y decidiendo cómo descomponerla en subconsultas más específicas.
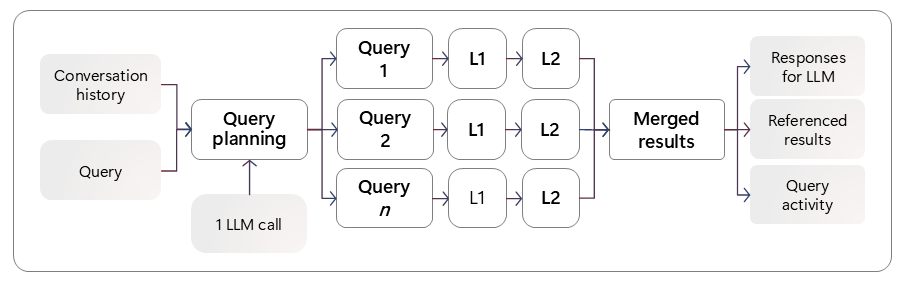
Pongamos un ejemplo práctico. Si preguntas sobre "las mejores estrategias de marketing digital para startups en 2024", un agente inteligente podría generar subconsultas como:
"Tendencias marketing digital 2024"
"Estrategias marketing startups bajo presupuesto"
"Herramientas marketing digital efectivas pequeñas empresas"
"Casos éxito marketing digital startups 2024"
Cada una de estas búsquedas especializadas encuentra información específica que luego se integra en una respuesta coherente y completa. Es como tener un equipo de investigadores trabajando en paralelo, cada uno especializado en un aspecto diferente de tu pregunta.
Los gigantes ya están jugando este juego
La adopción de esta tecnología no es algo que está por venir, ya está aquí. Bing Chat (Copilot) de Microsoft utiliza un LLM que analiza la pregunta del usuario, genera internamente varias consultas Bing y combina las respuestas antes de producir la respuesta final.
ChatGPT con búsqueda web hace algo similar, descomponiendo consultas complejas en búsquedas más específicas que luego integra. Perplexity.ai ha llevado esto aún más lejos, combinando la recuperación de información con cadenas de razonamiento para mejorar tanto la precisión como la transparencia en las fuentes.
La realidad es que, sin darte cuenta, probablemente ya has experimentado los beneficios de la búsqueda agentiva. Esa sensación de que estos nuevos buscadores "te entienden mejor" no es casualidad, es el resultado de sistemas que literalmente piensan antes de buscar.
El arte de descomponer vs. el arte de expandir
Aquí es donde la cosa se pone interesante desde un punto de vista técnico. Los investigadores han comparado diferentes enfoques para mejorar las búsquedas, y los resultados son reveladores.
La expansión semántica, que básicamente consiste en reescribir tu consulta con sinónimos y contexto adicional, tiene sus límites. La expansión semántica mejora la coincidencia consulta-documento, pero la descomposición explícita aborda problemas de intentos múltiples.
Es la diferencia entre usar un megáfono más potente versus usar varios altavoces estratégicamente ubicados. El megáfono puede hacer más ruido, pero los altavoces distribuidos llegan mejor a toda la audiencia.
También está el enfoque HyDE (Hypothetical Document Embeddings), que genera un documento hipotético para lanzar la búsqueda. Es una técnica inteligente, pero que funciona mejor en contextos muy específicos, como la recuperación zero-shot.
Por lo que parece, la descomposición de consultas mejora la relevancia de los resultados y la precisión en tareas de búsqueda complejas, medida mediante métricas estándar como Precision@k, MRR y nDCG. Los números no mienten y es que cuando la información está fragmentada entre múltiples fuentes, la estrategia de «divide y vencerás» simplemente funciona mejor.
No todo es color de rosa
Como en toda evolución tecnológica, la búsqueda agentiva viene con sus propios desafíos. El más obvio es la latencia. Mientras que una búsqueda tradicional puede darte resultados en milisegundos, la búsqueda agentiva necesita tiempo para pensar, planificar y ejecutar múltiples consultas.
Es el precio de la inteligencia, a mayor sofisticación, mayor tiempo de procesamiento. Los sistemas actuales han logrado optimizar esto bastante, pero sigue siendo un factor a considerar, especialmente en aplicaciones que requieren respuestas instantáneas.
Luego están los costos computacionales. Ejecutar múltiples búsquedas y procesarlas con modelos de lenguaje avanzados consume significativamente más recursos que una búsqueda simple. Para las empresas, esto se traduce en decisiones estratégicas sobre cuándo vale la pena activar la artillería pesada de la búsqueda agentiva.
El fantasma de las alucinaciones
Uno de los riesgos más sutiles pero importantes es el de las alucinaciones. Imaginar que un agente interpreta mal la intención del usuario, por lo tanto, podría generar subconsultas equivocadas, ergo, existe riesgo de alucinaciones.
Esto es particularmente problemático porque las alucinaciones en sistemas agentivos pueden ser más difíciles de detectar. Si una búsqueda tradicional te da un resultado irrelevante, es fácil notarlo. Pero si un agente interpreta mal tu intención y genera subconsultas incorrectas, los resultados pueden parecer coherentes pero estar fundamentalmente desviados de lo que realmente necesitas.
La solución que han adoptado los sistemas más sofisticados es la transparencia en las fuentes y la citación explícita. Cuando puedes ver exactamente de dónde viene cada pieza de información, es más fácil evaluar la calidad y relevancia de la respuesta.
La estrategia del uso inteligente
La estrategia es aplicar agentes de búsqueda de forma selectiva, para consultas sencillas no hace falta utilizar este tipo de agentes, pueden manejarse con búsqueda tradicional.
Es como usar un Lambo para ir a comprar pan (como si fueras un discípulo fantasmilla de LLados) técnicamente puedes hacerlo, pero probablemente no vale la pena. La clave está en desarrollar sistemas que sepan cuándo activar la búsqueda agentiva y cuándo conformarse con una búsqueda tradicional más rápida y económica.
Esto requiere una especie de meta-inteligencia que evalúe la complejidad de la consulta antes de decidir el método de búsqueda. Preguntas como "¿Cuál es la capital de Francia?" obviamente no necesitan descomposición agentiva. Pero consultas como "¿Cuáles son las implicaciones éticas y técnicas de implementar IA en sistemas de salud pública?" claramente se benefician del enfoque agentivo.
El futuro que ya está aquí
La evaluación de estos sistemas también ha evolucionado. Se ha desarrollado lo que llaman el "RAG triad" que es un conjunto de tres criterios que se utilizan para evaluar la calidad de las respuestas generadas por sistemas de inteligencia artificial que combinan recuperación de información y generación de texto, conocidos como sistemas RAG (Generación Aumentada por Recuperación)
Esto significa que ahora los mismos sistemas de IA que realizan las búsquedas también pueden evaluarse a sí mismos, creando ciclos de mejora continua. Es como tener un crítico interno que constantemente está revisando y mejorando el proceso de búsqueda.
Aplicaciones en el mundo real
Los casos de uso de la búsqueda agentiva van mucho más allá de simplemente encontrar información en internet. En atención al cliente, estos sistemas pueden descomponer consultas complejas de usuarios en subconsultas específicas que abordan diferentes aspectos del problema.
En investigación científica, pueden ayudar a los investigadores a encontrar literatura relevante que esté distribuida entre diferentes bases de datos y repositorios. En el ámbito empresarial, pueden facilitar la búsqueda de información que esté fragmentada entre múltiples sistemas internos (en este punto está una de las claves para el uso de la IA en el ámbito empresarial).
La clave está en entender que estamos ante un cambio de paradigma, pasamos de sistemas que simplemente buscan a sistemas que comprenden, planifican y ejecutan estrategias de búsqueda.
La revolución silenciosa continúa
Lo fascinante de la búsqueda agentiva es que representa un cambio fundamental en cómo las máquinas procesan nuestras necesidades de información. No es solo una mejora incremental, es un salto cualitativo hacia sistemas que realmente comprenden la complejidad de nuestras consultas.
Estamos viendo nacer una nueva generación de herramientas de búsqueda que no solo responden a nuestras preguntas, sino que las entienden en su contexto completo. Son sistemas que saben cuándo una pregunta simple requiere una respuesta simple, y cuándo una pregunta compleja necesita una estrategia sofisticada de investigación.
La próxima vez que uses ChatGPT con búsqueda web o Perplexity.ai y te sorprendas de lo bien que entiende tu pregunta compleja, recuerda que no es magia. Es la culminación de años de investigación en inteligencia artificial aplicada a la recuperación de información.
Y esto es solo el principio. A medida que estos sistemas se vuelvan más eficientes, más rápidos y más precisos, cambiarán nuestra relación fundamental con la información. Ya no tendremos que adaptarnos a los caprichos de los algoritmos de búsqueda, serán ellos los que se adapten a la complejidad natural de nuestras necesidades.
La búsqueda agentiva no es solo una mejora tecnológica, es el primer paso hacia un futuro donde la información realmente esté al servicio del conocimiento humano, y no al revés.
Referencias
Berntson, A., Stoica Beck, A., Salvador Aguilera, A., Quindós Sánchez, A., Gisselbrecht, T., & Chen, X. (2025, May 19). Up to 40% better relevance for complex queries with new agentic retrieval engine. Microsoft AI Blog – Azure AI Services techcommunity.microsoft.comtechcommunity.microsoft.com.
Chan, C. M., Xu, C., Yuan, R., Luo, H., Xue, W., & Guo, Y., et al. (2024). RQ-RAG: Learning to Refine Queries for Retrieval Augmented Generation. Preprint arXiv:2404.00610 arxiv.orgarxiv.org.
Lupart, S., Abbasiantaeb, Z., & Aliannejadi, M. (2024). Multi-aspect LLM Query Generation for Conversational Search (TREC iKAT 2024). Universidad de Ámsterdam, Informe de Experimentos arxiv.orgarxiv.org.
Wang, X., Wang, J., Cao, W., Wang, K., Paturi, R., & Bergen, L. (2024). BIRCO: A Benchmark of Information Retrieval Tasks with Complex Objectives. Preprint arXiv:2402.14151 arxiv.orgarxiv.org.
Gao, L., Ma, X., Lin, J., & Callan, J. (2023). Precise Zero-Shot Dense Retrieval without Relevance Labels. In Proceedings of SIGIR 2023. (Hypothetical Document Embeddings, HyDE) arxiv.orgarxiv.org.
Microsoft Learn. (2023). Develop a RAG Solution – Information Retrieval Phase (Agentic Queries) arxiv.org (documentación técnica sobre descomposición de consultas en RAG).
Epsilla. (2024, Nov). Advanced RAG Optimization: Query Decomposition (Whitepaper Técnico) blog.epsilla.comblog.epsilla.com.