


🍓 🤔Cuando la IA se pone a pensar
Qué ofrece o1-preview y o1-mini


Con los nuevos modelos liberados por OpenAI para uso y disfrute de sus usuarios llegamos a un nuevo punto de disrupción en el que, de manera subjetiva, vemos como un chatbot como ChatGPT se pone a pensar para darnos una respuesta.
Los rumores sobre el modelo Strawberry de estas semanas pasadas se han materializado con los modelos o1 y o1-mini en los que a la hora de ejecutar un prompt lo primero que vemos es que está “pensando”. Pero estos modelos traen consigo algunas restricciones en cuanto a su uso semanal: 30 mensajes para o1-preview y 50 para o1-mini. Además, hay otra limitación, de momento no se puede trabajar con archivos, ni generar imágenes.
Características clave del modelo o1 y cuándo aprovecharlas
El modelo o1 de OpenAI introduce mejoras significativas en su capacidad para resolver problemas complejos, posicionándose como una herramienta avanzada en el análisis lógico, matemático y de programación.
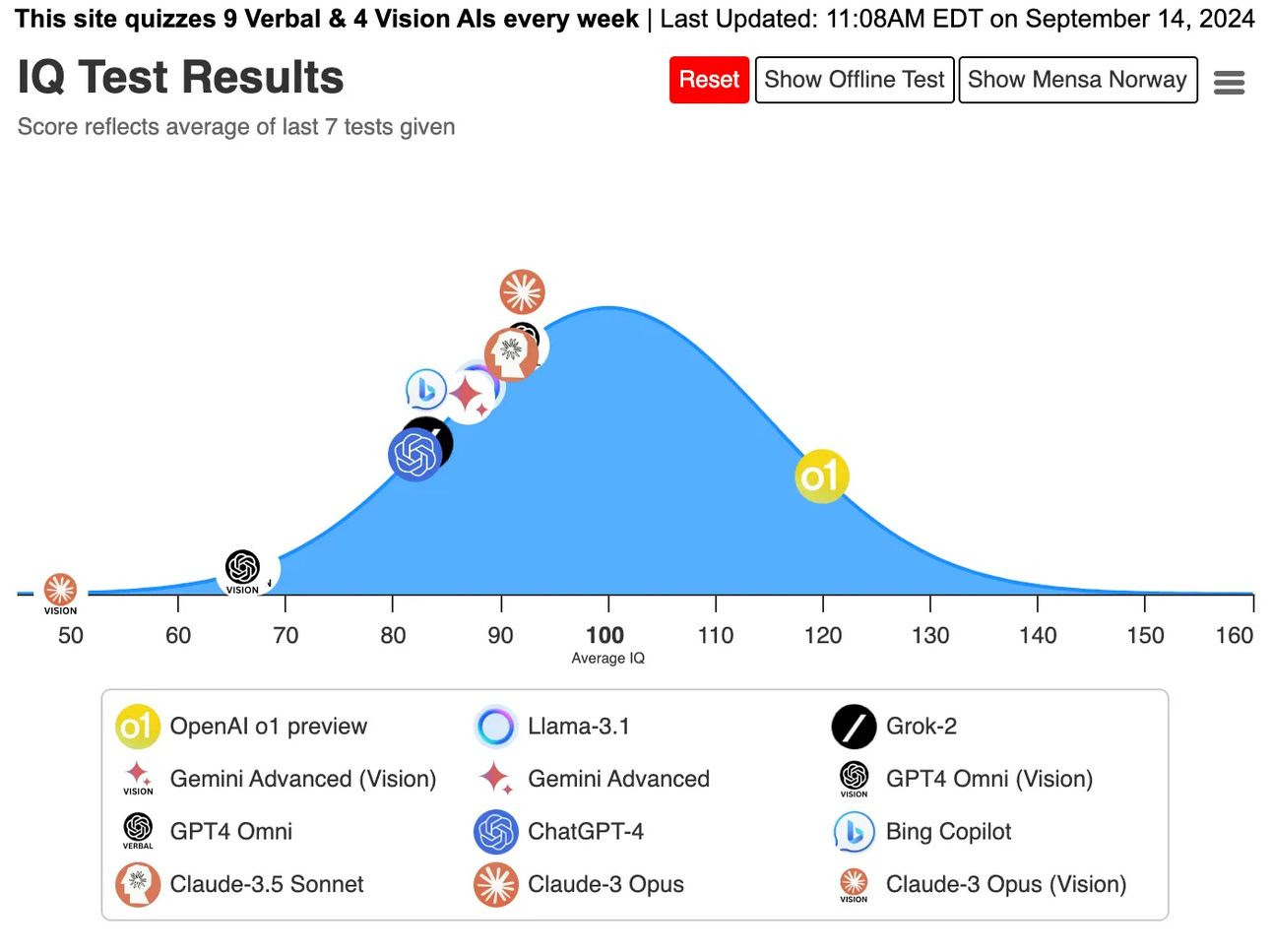
A modo de apunte, señalar que el nuevo modelo de OpenAI, o1 ha alcanzado un IQ de 120 en la prueba de Mensa en Noruega. A diferencia de modelos anteriores, o1 ha mostrado mejoras notables en su capacidad de razonamiento y reconocimiento de patrones, resolviendo con éxito problemas complejos, aunque aún comete algunos errores. Las pruebas indican que esta mejora no se debe al entrenamiento específico en tests de IQ, lo que refuerza la idea de que la IA podría superar la inteligencia humana en un futuro cercano, con importantes implicaciones para su desarrollo y su impacto en diversas industrias.
Capacidad de razonamiento avanzado
El modelo o1 sobresale en el manejo de problemas complejos, especialmente en el campo de las matemáticas y la programación. Ya se pueden ver multitud de ejemplos de programación de apps, juegos, webs y scripts a partir de un único prompt.
…
Esta capacidad lo convierte en una opción ideal cuando se requiere resolver problemas técnicos con alta precisión.
Mecanismo de cadena de pensamiento
La causa de que “piense” el modelo o1 es su uso del método de "cadena de pensamiento" o Chain of Thought, que permite realizar un razonamiento lógico profundo antes de generar una respuesta. Al seguir una secuencia lógica, similar al proceso de pensamiento humano, o1 logra mejorar la precisión y la transparencia en tareas de razonamiento complejo. Esto permite desglosar problemas grandes en partes más pequeñas, lo que facilita la comprensión y solución de problemas difíciles. Vamos lo que haría cualquiera a la hora de enfrentarse a un problema complejo.

Cuándo es conveniente utilizar este enfoque:
En análisis lógico que requieran varios pasos
En la explicación de procesos complejos en tareas científicas o técnicas
Al realizar análisis detallados donde cada etapa del razonamiento debe ser transparente
Cuándo, cómo y por qué utilizar los diferentes modelos de IA de OpenAI

Al trabajar con modelos de IA de OpenAI, es esencial elegir el adecuado según el tipo de tarea que se desea abordar, sobre todo teniendo en cuenta su limitación de uso.
ChatGPT o1-preview: Profundidad y razonamiento avanzado
Este modelo es ideal para situaciones en las que el tiempo de respuesta es menos importante que la precisión y el detalle de las respuestas. ChatGPT o1-preview se destaca por su capacidad de resolver problemas complejos, que requieren un análisis profundo y un enfoque multietapas. A pesar de su velocidad más lenta, el modelo brilla en situaciones donde se necesita una solución bien razonada y estructurada.
Cuándo usar ChatGPT o1-preview:
Resolución de problemas avanzados: Si necesitas afrontar una cuestión que necesite múltiples pasos y una descomposición detallada, este modelo es el indicado.
Investigación profunda: Para obtener respuestas que exploren múltiples ángulos y consideren diversos factores, o1-preview ofrece un análisis exhaustivo.
Prompts complejos: Si trabajas con información densa que necesita ser desmenuzada y organizada, este modelo lo hará de manera eficaz.
ChatGPT o1-mini: Respuestas rápidas y eficaces
Para tareas más sencillas y cuando quieras velocidad en la respuesta, el modelo ChatGPT o1-mini debe ser tu elección. Este modelo está diseñado para ofrecer respuestas rápidas y precisas, perfecto para situaciones en las que necesitas una solución de forma casi instantánea.
Cuándo usar ChatGPT o1-mini:
Tareas rápidas: Si tienes poco tiempo y necesitas una respuesta rápida y precisa, o1-mini es ideal.
Preguntas sencillas: Cuando se trata de resolver cuestiones que no requieren análisis profundos ni varias capas de información.
Decisiones basadas en datos: Para respuestas basadas en hechos y datos que necesitan una verificación rápida, este modelo es altamente eficaz.
Consejos para generar un buen prompt en estos modelos
La propia OpenAI proporciona documentación sobre estos modelos y algunos consejos sobre como interactuar con ellos. Nunca está de más tenerlos en cuenta:
Mantén los prompts simples y directos: Los modelos sobresalen en la comprensión y respuesta a instrucciones breves y claras, sin necesidad de guías extensas.
Evita los prompts de cadena de pensamiento: Como estos modelos realizan el razonamiento internamente, no es necesario pedirles que "piensen paso a paso" o que "expliquen su razonamiento".
Usa delimitadores para mayor claridad: Utiliza delimitadores como comillas triples, etiquetas XML o títulos de sección para indicar claramente las distintas partes del input, ayudando al modelo a interpretar correctamente cada sección.
Limita el contexto adicional en la generación aumentada por recuperación (RAG): Al proporcionar contexto o documentos adicionales, incluye solo la información más relevante para evitar que el modelo complique su respuesta.
¿Por qué hace pensar OpenAI a su nuevo modelo de ChatGPT?
Creo que es posible que existan motivaciones más profundas, incluidas comerciales, para mostrar un proceso de "pensamiento" mientras o1 genera su respuesta. Algunas razones que podrían haberlo motivado:
Mejora de la experiencia del usuario: Simular un proceso de pensamiento puede hacer que las interacciones se sientan más naturales y humanas. Cuando ves que el modelo está "pensando", se está imitando el ritmo de una conversación humana, lo que puede aumentar el compromiso y la satisfacción del usuario.
Gestión de expectativas: Mostrar ese “pensando” ayuda a gestionar las expectativas de los usuarios respecto al tiempo de respuesta. Si los usuarios saben que el sistema está procesando su solicitud, es menos probable que se impacienten o asuman que el sistema no está funcionando.
Percepción de reflexión: Una breve pausa antes de entregar una respuesta puede dar la impresión de que el modelo está considerando la pregunta, por lo tanto, percibir la respuesta como más reflexiva o precisa.
Construcción de confianza: Si crees que parece que está trabajando en tu solicitud en lugar de proporcionar respuestas instantáneas, que podrían percibirse como enlatadas o genéricas, aumentará tu confianza.
Diferenciación comercial: Desde una perspectiva de marketing, es un elemento diferencial, al menos de momento. Puede hacer que parezca más avanzada o fácil de usar en comparación con otros modelos.
Consideraciones técnicas: Puede servir también para cubrir retrasos reales en el procesamiento debido a la complejidad o la latencia de la red.
Métricas de compromiso del usuario: Como en todo lo digital, los kpis, las métricas son lo que importan a la hora de demostrar resultados. Así que tiempos de interacción más largos pueden ser beneficiosos para mostrar más compromiso por parte del usuario. Ese “pensando” puede aumentar el tiempo que los usuarios pasan interactuando con la aplicación.
Una última advertencia
OpenAI ha reconocido que sus nuevos modelos de IA, conocidos como o1 o "Strawberry", presentan un mayor riesgo de uso indebido, especialmente en la creación de armas biológicas y en el ámbito de la persuasión. Es el nivel de riesgo más alto asignado por OpenAI a GPT hasta ahora.

Creo que no son muy útiles de momento. Por un lado, si usas ChatGPT, está limitadísimo (30/50 prompts por SEMANA para o1/o1-mini). Por otro lado, llámame desconfiado, pero tiene pinta de que te puedas llevar algún susto si lo usas por API o en Playground, por su mayor coste y porque no sé si van a contar como tokens de output los que genera "pensando". Si es así va a generar un coste variable que depende de lo poco o mucho que piense.
Yo no lo voy a tocar ni con un palo hasta que no lo hayan optimizado un poco. Cuando saquen el o1 completo quizás.
Y son mejores para crear contenido?